










Como ya he dicho en muchas otras ocasiones, en mi opinión las expresiones regulares son una de las herramientas más potentes que puede aprender un programador, y no solo para programar ya que sirven también en muchos entornos y herramientas.
Hoy me voy a detener a explicar con detalle el funcionamiento de una característica potente e infrautilizada de las expresiones regulares y que muchos programadores no entienden bien por lo que he podido comprobar. Se trata de las búsquedas anticipadas (lookahead asssertions en inglés) y las búsquedas retrasadas (lookbehind asssertions en inglés), que colectivamente se suelen denominar “Búsquedas alrededor” (del inglés lookaround asssertions).
Nota: la traducción al español de asssertion sería “afirmación” o “aserción”, pero en mi humilde opinión se entiende mucho mejor “búsqueda” en este contexto y es por eso que siempre he usado esta palabra en mis libros, artículos y cursos y por eso la verás usada aquí también así.
Vamos a ver en qué consisten y cómo funcionan.
Búsquedas anticipadas
Desde que se presentaron las expresiones regulares en JavaScript hace 20 años, en 1999, se soportaban ya las búsquedas anticipadas tanto positivas como negativas. Vamos a ver en qué consisten.
Búsquedas anticipadas positivas
Una búsqueda anticipada positiva se define mediante el uso de la expresión (?=...), siendo los puntos suspensivos el valor a buscar. Permiten localizar un patrón que vaya justo a continuación de otro, pero solamente captura al primero.
Por ejemplo, la expresión regular /Windows\s(?=7|8|10)/ coincide con el primer “Windows” en la frase "Windows 8 fue muy polémico, más incluso que Windows Vista", pero no coincide con el de “Windows Vista” del final de la frase. Solamente devuelve “Windows” como resultado de la búsqueda, obviando el “8”. Este es su aspecto visual si la analizamos con RegExper:
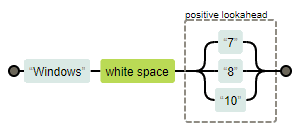
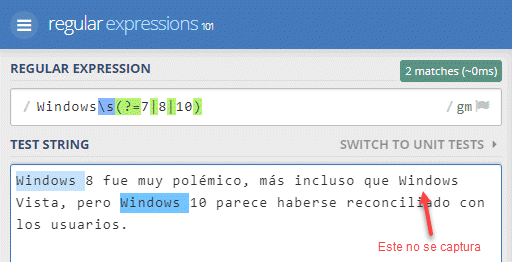
Si lo probamos en Regex101 con una frase como la anterior que haga mención a varias versiones de Windows, vemos que solamente captura la palabra "Windows " (con el espacio incluído) cuando va seguido de 7, 8 o 10, pero no en otros casos, que es justo lo que queremos:
Otro detalle sutil pero importante a tener en cuenta es que estas búsquedas anticipadas no consumen caracteres, es decir, después de que se produce una coincidencia, la búsqueda de la siguiente coincidencia comienza inmediatamente después de la anterior, no después de los caracteres que componen la cadena de búsqueda anticipada. Un ejemplo tonto de esto para entenderlo… Si tenemos la expresión regular /[abcd](?=ab|cd)/ lo que quiere decir es que va a buscar cualquiera de las letras a, b, c o d que vayan seguidas de las dos letras ab o dos letras cd. O sea:
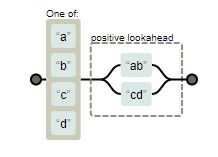
Si buscamos con esa expresión regular dentro de en la cadena "aabcd" esto es lo que se encuentra:
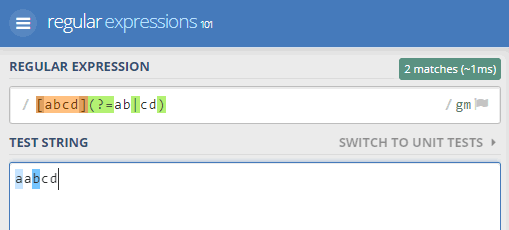
Se localizan tanto la primera a como la b. El motivo es el explicado: la parte de la búsqueda anticipada no se cuenta para el avance de la búsqueda, reanudándose ésta a partir de la parte encontrada que vaya delante de los paréntesis. Así, en la primera coincidencia (que son las tres primeras letras aab), se reanuda la búsqueda no después de estas 3 letras, sino después de la primera de ellas (la a) que es la coincidencia que se captura. Por lo tanto puede encontrarse la segunda coincidencia bcd, que de otro modo no se encontraría.
Si te preguntas cómo hacer para que se haga la captura de la cadena completa, es decir, en este ejemplo tonto que se capture aab y no solo la a y por lo tanto se continúe a partir de estos tres caracteres, la expresión correcta sería: /[abcd](ab|cd)/:
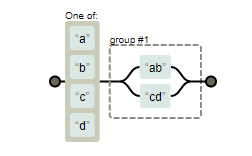
que solo obtendría como resultado aab, pero ya no bcd puesto que seguiría buscando a partir del cuarto carácter puesto que captura todos. ¿Ves la diferencia con el anterior?
Suena lioso pero no lo es si te paras un poco a pensarlo y lo pruebas con las herramientas que te estoy referenciando.
Búsquedas anticipadas negativas
Las búsqueda anticipadas negativas funcionan de manera idéntica a las anteriores pero a la inversa. Es decir, en lugar de considerar las coincidencias consideran las no-coincidencias.
Se denotan con una expresión como esta: (?!...), o sea, con una admiración final en lugar de un igual, siendo los puntos suspensivos el modelo con el que no queremos coincidir.
Por ejemplo, la expresión regular /Windows\s(?!7|8|10)/ haría justo la búsqueda inversa a la que hicimos antes, evitando las menciones a Windows 7, 8 o 10:
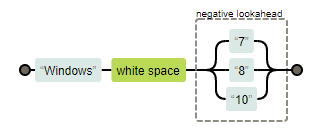
Si ahora la ejecutamos para ver cóm actúa, veremos que localiza el "Windows " de “Windows Vista”, pero no lo hace con ninguno de los otros:
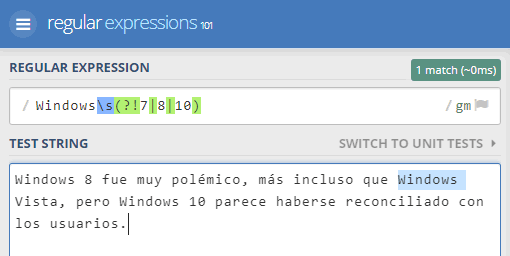
Al igual que las anteriores, la captura no incluye la expresión dentro del paréntesis, por eso es anticipada, con los mismos efectos que en el caso anterior.
Búsquedas retrasadas
Una de las novedades de ECMAScript 2018 o ES9, presentado en junio de 2018, fue la introducción de este tipo de búsqueda que antes no estaban soportadas.
Importante: en el momento de escribir esto solo están soportadas por Chrome 75 o posterior (incluyendo en móviles Android) y los navegadores que comparten su motor, es decir, Opera, las nuevas versiones de Edge y otros menos conocidos como Brave o Vivaldi. Firefox no le da soporte todavía (aunque están en ello) , ni tampoco Safari. Por lo tanto conocerlas está muy bien pero no conviene usarlas todavía en aplicaciones abiertas en Internet donde no controlemos los navegadores que se van a utilizar. Las anteriores, sin embargo, funcionan en todos los navegadores, incluso versiones muy antiguas de Internet Explorer.
Las búsquedas retrasadas son similares a las que acabamos de ver pero se colocan delante del patrón que queremos localizar, no detrás.
Se denotan con una expresión del tipo (?<=...) en el caso de las positivas y (?<!...) en el caso e las negativas. O sea, como las anteriores pero añaden un símbolo de menor delante del igual o de la admiración.
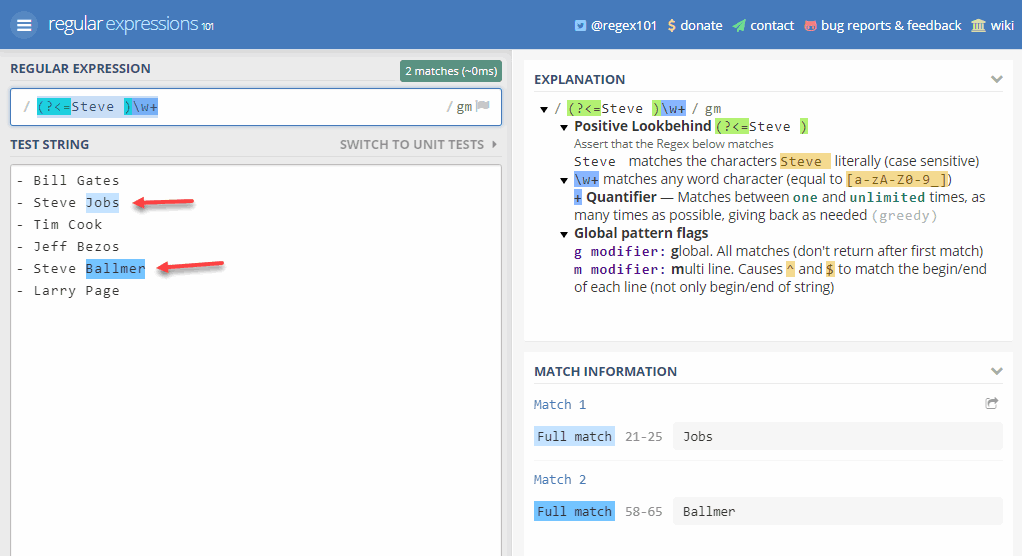
Por ejemplo, por poner un ejemplo “geek”, supongamos que queremos localizar en una lista de nombres todos los apellidos de personas que se llamen “Steve”, desechando los apellidos de otras personas de la lista. Esto es muy fácil de conseguir con una expresión de búsqueda retrasada positiva como esta: (?<=Steve )\w+ que se representaría visualmente así:
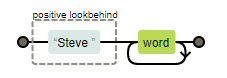
Nota: por desgracia Regexper no soporta todavía las búsquedas retrasadas, así que en este caso he tenido que simular el gráfico a mano, pero esto sería lo que mostraría en caso de soportarlas.
Y si la ejecutamos en Regex101 con una lista veremos cómo identifica rápidamente todos los apellidos ilustres de los Steve que hemos metido en la lista (en este caso hay 2):
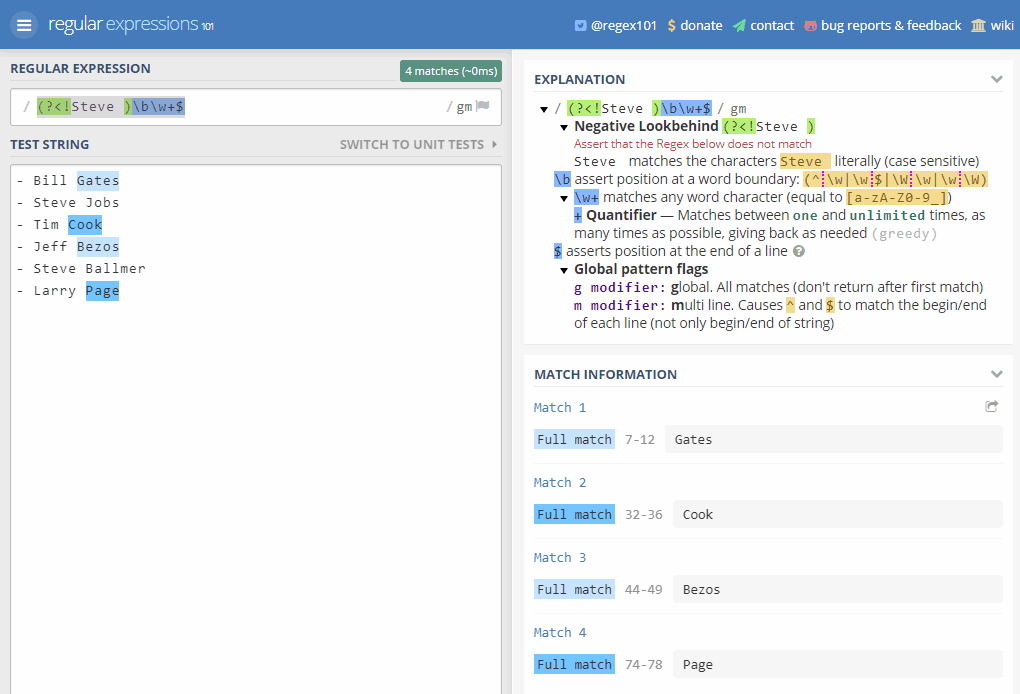
Lo mismo se puede hacer a la inversa con una búsqueda retrasada negativa, de modo que en nuestro ejemplo localice todos los apellidos de la lista de gente que no se llame Steve. Lograr esto es un poco más complicado ya que ahora debemos indicar más condiciones o nos localizará cosas que no son apellidos, ya que si solo ponemos (?<!Steve )\w+, cualquier palabra que no lleve delante Steve nos valdrá, y eso incluye los propios nombres. Por lo tanto la expresión sería: (?<!Steve )\b\w+$ que nuevamente he simulado en Regexper para que se vea claro su significado:

Se busca cualquier fragmento de texto que esté al final de una línea, que sea una palabra entera y que no esté precedida por “Steve “. Otra opción similar habría sido quitar el espacio de “Steve ” y ponerlo en el patrón a buscar, así: (?<!Steve)\s\w+$ pero nos localizaría los apellidos con el espacio delante (podríamos obtener solo el apellido rodeándolo con un paréntesis para luego poder extraerlo como una subcaptura/subgrupo).
Bien, usando esta expresión podemos ver que localiza perfectamente los apellidos de los no llamados Steve:
consiguiendo lo que esperábamos.
Nota: cabe destacar que tanto en el caso de las búsquedas anticipadas com en el de las retrasadas podemos usar varias seguidas, una tras otra, para combinar varias condiciones. NO es tan frecuente verlo pero funciona perfectamente.
En resumen
Las expresiones regulares son una herramienta súper-potente a la que deberíamos aprender a sacar partido a fondo. Si vamos más allá de lo básico pueden llegar a ser muy complejas y bastante crípticas, pero pueden ahorrarnos horas de trabajo en muchas tareas.
En esta ocasión hemos estudiado cómo funcionan las búsquedas adelantadas y retrasadas, de las que no todo el mundo tiene claro su funcionamiento, con algunos ejemplos prácticos. Aunque me he enfocado en JavaScript, en realidad todo lo explicado sirve para casi cualquier otro lenguaje de programación que soporte expresiones regulares, como Java, .NET/C#, Ruby, PHP… así que, como cualquier cosa que aprendas sobre expresiones regulares, te servirá igualmente en cualquier lenguaje o entorno.
Publicada el16 octubre, 2019 @ 15:00
Deja una respuesta